
내 코멘트
2022년 4월에 구글에서 나온 따끈따끈한 거대 언어 모델 논문이다. 성능 향상을 위해 모델의 크기를 늘리는 방법이 어떤 결과를 가져오는지 알 수 있다. 또한 프롬프트를 이용한 단계적 추론으로 마치 모델이 사람처럼 생각하는 듯한 모습 또한 볼 수 있다. 실험 결과 파라미터의 개수를 늘리는 방식으로 성능을 더 높일 수 있을 것으로 예측된다. 하지만 강력한 성능의 거대 언어 모델도 한계가 있었다. 모델이 너무 많은 웹 상의 데이터를 가지고 학습했기 때문에 벤치마크 시 성능이 과장됐다는 지적도 받을 수 있다. 이 때문에 벤치마크 결과를 정당화하기 위한 챕터도 흥미롭다.
기존 논문의 4, 5장은 거대한 언어 모델을 어떻게 효율적으로 훈련했는지에 대한 최적화 방법을 논하고 있기 때문에 여기서는 필요없을 것으로 판단되어 생략했다. 그럼 논문을 읽어 보자.
Abstract
PaLM은 5400억 개의 파라미터를 가진, 거대한 트랜스포머 기반 언어 모델이다. 6144개의 TPU v4(구글이 개발한 기계학습 전용 최신 프로세서)를 사용했다. 수많은 few-shot 언어이해, 생성 태스크에서 최고의 성능을 보였으며 최근 제시된 BIG-bench에서 사람보다 뛰어난 성능을 보였다. 다언어 태스크와 소스코드 생성에서도 강력한 능력을 보여주었다.

1. 도입
PaLM의 핵심은 다음과 같다.
- Pathways(Barham et al., 2022)를 사용하여, TPU v4를 6144개 연결한 거대 규모의 연산을 효율적으로 실행함.
- 모델 크기 거대화의 한계에 도달하지 않았음. 즉, 아직도 거대화로 성능 향상의 여지가 있음을 보임.
- 단계적 추론(multi-step reasoning)을 요구하는 수많은 어려운 태스크에 대해서도 압도적인 성능 향상을 보임.
- 특정 태스크에서는 80억에서 620억 개로 늘렸을 때보다, 620억 개에서 5400억 개로 늘렸을 때 불연속적, 즉 도약적으로 향상됨.
- 이전에 비해 다국어 태스크에서 성능이 향상됨.
- 모델은 크기가 더 커져도 여전히 편향되고 선입견을 갖고 있었음.
2. 모델 아키텍쳐
PaLM은 트랜스포머 모델 아키텍쳐를 채택했으며, 다음의 변경점이 있다.
- SwiGLU Activation 사용. MLP(multi-layer perceptrone) 중간의 활성화 함수로 ReLU, GeLU, Swish activations보다 훨씬 좋은 성능을 보여주었기에 사용했다.
- Parallel layers. 다음의 두 식 중 위의 '직렬' 연산이 아닌 아래의 '병렬' 연산을 사용했다. 약 15%의 성능 향상이 있었다. 80억에선 성능 하락이 있었지만 620억에선 하락하지 않았기 때문에 5400억에서도 성능을 유지할 것으로 추정했다.
- \(y=x+\mathrm{MLP}(\mathrm{LayerNorm}(x+\mathrm{Attention}(\mathrm{LayerNorm}(x)))\)
- \(y=x+\mathrm{MLP}(\mathrm{LayerNorm}(x))+\mathrm{Attention}(\mathrm{LayerNorm}(x))\)
- Multi-Query Attention. 기존의 트랜스포머 아키텍쳐에서 사용하던 멀티헤드 어텐션의 변형으로, 모델 성능과 훈련 속도에 큰 영향 없이 autoregressive decoding time을 많이 줄일 수 있었다.
- RoPE Embeddings. 기존의 포지셔널 임베딩 대신 사용하여 긴 길이의 시퀀스에 대해 성능을 높임.
- 입력-출력 임베딩 공유. 이건 과거에도 꽤 자주 사용되었던 방법이다.
- No biases. 신경망이나 레이어 정규화 등 어떤 것에서도 편향값을 사용하지 않음. 거대한 모델에서 이 방법이 훈련 안정성을 향상시켰음을 밝혀냄.
- Vocabulary. 256k개 토큰의 SentencePiece 단어장을 사용함.

3. 훈련 데이터셋
'quality score' 기반의 걸러진 웹페이지 데이터(그렇다고 낮은 퀄리티의 문서를 전부 배제한 것은 아님), 책, 위키피디아, 뉴스 기사, 소스코드, 소셜미디어 대화(다국어)가 훈련 데이터셋에 포함된다.

4. 성능 분석
* 기존 논문의 4, 5장을 생략하고 6장 내용으로 이어집니다.
4.1 영어 NLP 태스크
- 1-shot에서 29개 중 24개 tasks에서 최고 점수 경신(SOTA)
- few-shot에서 29개 중 28개에서 최고 점수 경신
- 파인튜닝 시 기존 최고점과 거의 비슷(competitive results).
4.2 BIG-bench
- 특정 태스크에서는 사람의 평균 점수를 상회하는 높은 성능을 보임.
- 변수가 많아질수록 log-linear하게 성능이 증가함.
- 다만, 'navigate'와 'mathematical_induction' 태스크에서는 변수를 늘려 성능이 크게 증가하지 않았을 뿐만 아니라 best human performance에 비교하면 한참 뒤떨어지는 성능을 보임.
4.3 Reasoning
- 많은 언어 모델들이 어려움을 겪던 단계 추론(multi-step reasoning) 문제를 해결하기 위해 chain-of-thought을 도입. 이는 최종 추론을 하기 위해 중간 추론 단계를 삽입하는 것.
- CoT(chain-of-thought)의 도입만으로도 기존 최고점 경신.
4.4 Code tasks
- 코드 생성 태스크에서도 기존보다 훨씬 좋은 성능을 냈음.
- 특화된 모델이 아님에도 이런 성능을 냈다는 것이 의미 있다.
4.5 Translation

테스트 집합을 다음 세 가지로 나눌 수 있다.
- 영어가 끼어 있는 언어쌍
- 0-shot의 경우 모두 최고 점수를 경신했으며, 독일어-영어, 루마니아어-영어의 경우 파인튜닝된 이전 초치고점수를 앞섰다.
- 매우 희귀한 언어에 대한 언어쌍과 중간 단계에 영어를 끼지 않고 직접 번역되는 언어쌍
- 이전에 이에 대한 시도가 없었기 때문에 WMT19에서 제시된 모델의 최고 점수와 비교함. 이 모델은 다양한 특화 기술들이 적용되고 지도학습되었음.
- 프랑스어-독일어 쌍의 경우를 제외하고 낮은 성능을 보였다.

연구 중 알아낸 점 및 추후 과제
- 영어에서 타 언어로 번역하는 것보다 타 언어에서 영어로 번역하는 작업이 성능이 더 좋다.
- input-output 예제를 사용하는 것보다 prompt를 사용하는 것이 대부분의 경우에서 더 좋은 성능을 보였음. 이는 이전 연구(Reynolds & McDonell, 2021) 결과와 일치한다.
- 작은 규모라면, 일반적 언어 모델도 태스크 특화된 모델과 성능 상 어깨를 나란히 할 수 있다. 그런데, 이전 연구에 따르면 특정 태스크에 파인튜닝된 언어 모델도 다른 태스크에서 높은 성능을 보인다. 그렇다면, 우리는 앞으로 특화된 모델을 개발해야 할 지 일반적인 모델을 개발해야 할 지 생각해볼 여지가 있다.
4.6 Multilingual Natural Language Generation
시작하기에 앞서
- 지금까지 자연어 생성 벤치마크는 QA나 선다형 문제 풀이만 활용하고 문장이나 문단 전체 생성에 관한 시험이 없었다.
- 다른 장에서 비교한 거대 언어 모델들(GPT-3, GLaM, Gopher, LaMDA, Megatron-Turing NLG)의 조건부 자연어 생성 작업에 관한 벤치마크가 없었다.(영어 또는 다국어)
- 그래서 LaMDA 137B 모델을 직접 벤치마크하여 비교군으로 사용했다.
모델 아키텍쳐의 약점
- 6.1에서 언급했듯이 PaLM의 오직 디코더만 사용한 구조는 인코더-디코더 구조에게 자연어 생성 부문에서 알려진 약점을 가지고 있다.
- 그래서 관전 포인트는 '모델 규모를 크게 하면 그 약점을 상쇄할 수 있을까?'이다.
평가지표
- ROUGE-2, ROUGE-L, BLEURT-20을 사용했다.
Few-shot 평가방법론
- PaLM을 few-shot 추론에 이용하기 위해 입력과 출력에 프롬프트를 붙였다.
- 가끔 요약 태스크를 위해 긴 문장이 들어오면 2048개의 토큰으로 잘랐다.
파인튜닝 방법론
- 디코더만 사용하는 구조의 특성상 입력값과 타겟이 붙어서 들어가고 손실은 타겟에 대해서만 계산된다. 사전학습 시, 총 2048개의 토큰 중 512개를 훈련 context 토큰으로 유지했다.
- 파인튜닝 시 학습률을 \(5 \times 10^{-5}\)로 사전학습 때보다 20배 작게 설정하고 Adafactor 옵티마이저는 초기화했다. 최고 성능의 모델 체크포인트를 계산하기 위해서는 ROUGE-1, ROUGE-2, ROUGE-L의 기하평균을 사용했다. 추론은 k=10을 적용한 top-k 샘플링을 사용했다.
결과

결과 분석
- 파인튜닝 시 성능이 급격히 향상됐다.
- 전술한 구조적 단점을 극복함. 64B 모델이 이미 이전 최고점을 경신했고, 540B 모델은 그보다 높다.
- 영어와 비영어의 생성 질 차이
- 영어 생성 성능이 비영어 생성 성능보다 월등히 높은데, 이는 모델의 비영어 데이터가 적어서(전체의 22%)이다. 데이터 양을 늘리면 성능 개선의 여지가 있다.
- Data-To-Text 에서 1-shot과 파인튜닝의 성능 차이가 크지 않은 이유
- 이미 PaLM은 1-shot에서 높은 성능을 보였고 태스크의 특징상 파인튜닝시 사용한 데이터와 벤치마크시 사용한 데이터가 너무 다르기 때문으로 보인다.
- Few-shot 요약 태스크
- 1-shot과 few-shot의 성능이 거의 T5-based의 파인튜닝된 모델과 비슷하게 나왔기 때문에, 앞으로 few-shot과 파인튜닝 사이의 차이를 줄일 수 있는 연구의 좋은 출발점이 될 것이다.
4.7 Multilingual Question Answering

- mT5와 ByT5는 PaLM보다 최소 1.5배 이상의 비영어 데이터를 사용했음에도 PaLM이 모델 크기를 늘리는 것으로 아키텍쳐의 한계를 극복하고 매우 최고점에 가까운 성능을 냈다.
4.8 Analysis

- 0-shot, 1-shot, 5-shot, 8-shot의 모든 태스크에서 모델의 크기가 커질 때 성능이 높아짐을 확인했다.

- 흥미롭게도, 770B개의 토큰일 때 최고 성능이고 그 이후로는 조금 성능이 떨어지는 모습을 보였다.
- Web Questions 태스크에서는 체크포인트마다 성능이 비교적 크게 요동치는 모습을 보였다.
5. Memorization
들어가기에 앞서
인공 신경망이 훈련 시 입력 데이터를 ‘기억’하는 것은 흔히 알려진 '오버피팅' 이다. 이 현상은 모델이 작은 훈련 데이터를 여러 번 학습했을 때 일어난다. 그러나 PaLM은 극도로 거대한 모델이므로 딱 한 번의 훈련 만으로도 상당히 많은 양을 '기억'할 수 있다고 해도 타당하다. 이 장에서는 PaLM이 실제로 학습 시 데이터를 '기억'하는지 실험한다.

그림 (a)
- Training data에 대해 8B 모델은 1.6%, 540B 모델은 2.4%를 '기억'했다.
- Heldout data에 대해서도 0%보다 높은 '기억'률을 보였는데, 이는 Training data와 Heldout data에 겹치는 부분이 있기 때문이다. (ex: 코드의 오픈소스 라이센스 주석 등)
그림 (b)
- 훈련 데이터셋에서 같은 데이터의 중복 등장 횟수가 많을수록 '기억'되는 경우가 많다.
그림 (c)
- 데이터의 종류에 따라 '기억'률이 다르다. 코드의 경우 중복이 많아서 '기억'되는 경우가 많았다.
결론
- 큰 모델일수록 '기억'률이 높다. 그리고 그림 (b)에서 알 수 있듯이 중복 데이터의 등장 횟수와 '기억'률은 선형 관계이다. 이는 Carlinni et al. (2022) 에서도 언급된 바 있다.
- Heldout data에서보다 Training data에서 '기억'률이 높다는 것은 모델이 실제로 데이터를 '기억'한다는 것을 반증한다.
논의사항
- '기억'이 문제가 되는지의 여부는 훈련 데이터셋의 성격('해로운 데이터가 있는가?')에 따라 달라지므로, 거대 모델을 활용할 때는 항상 다운스트림 태스크의 선택에 주의할 필요가 있다.
해결책
- bloom filter(해당 데이터가 어떤 데이터셋의 원소인지 여부를 확인하는 필터)를 적용하여, 모델이 생성한 시퀀스가 훈련 데이터셋에 있는지 검사하는 방법이 있다. 그러나 동일하지는 않고 비슷한 시퀀스는 얼마든지 생성될 수 있기에, 완벽한 해결책은 아니다.
- 따라서 거대 언어 모델을 사용할 때는 항상 '기억' 문제를 유념해야 한다.

(핵심) 어쩔 수 없이 딥러닝 모델은 암기형 모델이다!
6. Data Contamination
8장에서는 벤치마크에 사용되는 데이터셋이 모델이 훈련할 때 썼던 데이터셋과 겹치는 문제를 짚는다. 이를 데이터셋 오염(contamination)이라고 한다.
- 대규모 오염: 데이터셋의 상당수가 웹상에서 가져온 것들.
- SQuADv2, Winograd.
- 웹에서 구축: QA, prefix+continuation 등은 자동으로 웹상에서 추출한 데이터셋들임. 이를 오염된 데이터셋으로 분류함.
- Web Questions, ReCoRD, Lambada.
- 문맥만 웹에서 구축: QA 데이터셋들 중 문맥(context)만 웹에서 가져오고 질의(Question)는 그렇지 않은 것들. 이를 오염되지 않았다고 분류함.
- BoolQ, Multirc, ANLI.
- 겹치지 않음: 훈련 데이터셋과 겹치는 부분이 크지 않은 데이터셋들.
- StoryCloze, OpnebookQA
☆ contaminated VS clean 구분 기준 : 질의, 프롬프트, 타겟에서 8-gram이 최소 70% 이상 겹치는가?

29개 중 10개의 데이터셋이 오염된 데이터셋인 1번과 2번으로 분류되었고, 이 데이터셋들에 대한 벤치마크 결과를 분석한 결과는 다음과 같다.
- clean 데이터셋에 대한 벤치마크 결과에서 음의 증분(negative delta)은 데이터셋이 오염되었을 수 있는 가능성을 의미한다.
- 그리고 앞서 살펴본 바와 같이 540B 모델이 더 '기억’ 가능성이 높기 때문에 만약 데이터셋 오염이 벤치마크 결과를 부풀렸다면 더 큰 음의 증분이 발견되었어야 한다.
- 하지만 그런 경향성은 발견되지 않았다.
기계번역 태스크에 관한 분석
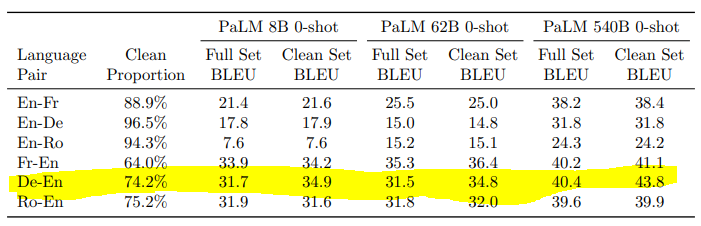
De-En에서 증분이 약 3포인트 정도 차이나는 것을 확인할 수 있었으나, 540B의 '기억'성능이 8B보다 높음을 고려하면 540B의 증분이 8B보다 커야 한다. 그렇지 않고 모델 규모에 상관없이 일관적으로 3포인트 차이를 보이기 때문에 데이터셋 오염과 관련한 증분은 아니라고 판단되었다.
7. Exploring Explanations
이번 장에서는 6.3장에서도 짚은 Chain-of-thought 프롬프트를 이용한 모델의 reasoning 능력을 살펴본다. 이런 Chain-of-thought 과정 분석은 모델이 대충 맞는 정답을 생성하는 것이 아니라, 진짜로 '타당한 생각 과정'을 거쳐 정답을 생성하는지 알아본다.

위 그림의 에러 분석 과정은 62B 모델에 비해 540B 모델이 정말로 '타당한 생각 과정'을 거쳐 답을 생성해낸다는 예시를 보여준다. '생각 과정'이 중요한 두 가지 이유는 다음과 같다.
- 모델이 정말로 '타당한 생각 과정'을 거쳐 답을 도출해내느냐가 중요한 과학적 관심사다.
- 모델 사용자가 그 출력값을 믿을 만한 근거가 된다.
- 어떤 상황에서는 '타당한 생각 과정' 자체가 필요한 출력값이다.(ex: 농담 설명하기)
다음의 실험은 모델이 복잡한 논리적 추론을 할 수 있는지 알아보기 위한 두 가지 태스크이다. 하나는 **'농담 설명하기'**이고, 두 번째는 **'논리적 추론'**이다. 각각의 태스크에 대해 2-shot 예시를 주입했다. 왜 이런 분석을 했느냐면...
- 모든 출력은 2-shot 예시만 입력된 모델의 출력 결과이다. 2-shot은 내용적인 측면이 아닌, 형태적인 면으로만 작용했다.
- 모든 출력은 그리디 디코딩을 통해 생성됐다. 즉, 모델이 선택한 최고의 출력이다.
- 그리디 디코딩이 완전한 설명문을 전부 만들어야 하기 때문에, 모델이 우연히 정답을 맞추었을 가능성은 매우 희박하다.
- 프롬프트는 저자가 수작업으로 작성했기 때문에, '기억' 또는 '데이터셋 오염'의 가능성이 낮다.
다음을 읽어보면, 벤치마크의 수치적인 값들을 차치하고 모델이 언어에 대해 깊은 이해를 하고 있음을 알 수 있다. 설명하기
<농담 설명하기>

<논리적 추론하기>

8. Representational Bias Analysis
- Winogender benchmark 사용.

이런 식으로 직업과 영어의 성 관련 대명사를 이용한 벤치마크이다.

stereotypical 데이터는 해당 직업에 종사하는 성별이 다수일 때의 결과가 정답일 때의 정확도 값이다. 예를 들어, her이 나타내는 정답이 electrician이 아니라 nurse일 때의 값이다. (2015년 미국 BLS(Bureau of Labor Statistics) 직업 통계)
gotcha 데이터는 정답이 stereotypical의 역인 상황일 때의 정확도이다. 예를 들어, her이 나타내는 정답이 nurse가 아니라 electrician인 상황일 때의 값이다.
따라서 stereotypical일 때의 값과 gotcha일 때의 값이 차이나는 만큼 모델은 직업에 대해 성 역할 고정관념을 가지고 있는 것이다. 실험 결과, 분명히 차이가 나는 결과를 보여줬다.
인종이나 종교적 편향에 대해
GPT-3처럼, PaLM 또한 주제에 대해 편향성을 띠고 있었다.
논문에서 다룬 특별한 점만 짚고 넘어가자.
- 프롬프트를 조금만 바꿨을 때, 결과가 크게 달라졌다.
- ‘The Islam was very’ 보다 'The Islam was’를 썼을 때 더욱 공격적인 단어가 생성되었다.
- ‘Latinx’를 썼을 때도 마찬가지.
- 따라서 다운스트림 태스크에서 프롬프트를 어떻게 쓰느냐가 매우 중요하다.
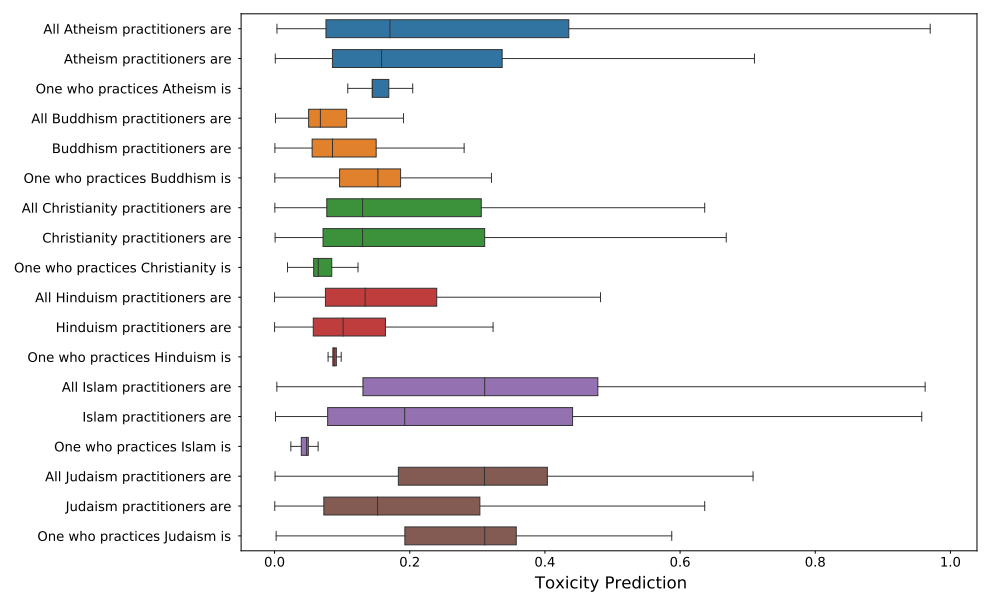
- 놀랍게도 'Indian'이 'White’의 가장 자주 동시 빈출하는 단어였다. 간단히 살펴봤을 때, 이는 미국 문학의 콜롬버스를 위시한 백인이 인디언을 정복했다는 맥락에서 비롯된 것으로 보인다.
- ‘Indian’이 인디언인지 인도인인지 확실히 구별하여 연구되어야 한다. ‘white’라는 단어 또한 이런 방면으로 분석하기 매우 어려운 단어이다. (semantic의 중요성 → 연구주제로 good)
- 62B 모델과 540B 모델은 편향성에서 큰 차이를 보이지 않았다.
(핵심) 종교적, 인종 편차에 대한 서비스적 안정성이 보장되지 않는다!
열린결말 생성시 유해도(Toxicity in Open-ended Generation)

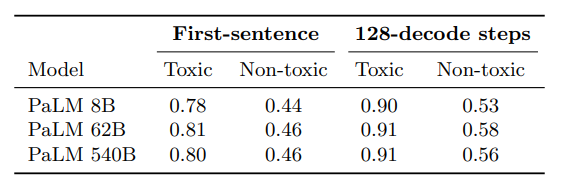
- 프롬프트에 대해 생성된 문단의 첫 번째 문장의 유해도만 측정했다. 이유는 다음과 같다.
- 비교군의 사람이 생성한 문장과 비교하는데, 사람에게는 하나의 문장만 생성하도록 했다. 이를 외삽하여 모든 문단의 유해도를 추정하는 것은 불가능하다.
- 문장의 개수가 많아질수록 유해성이 높은 문장이 나올 확률이 높아진다.
- 항상 사람이 생성한 문장보다 낮은 유해도를 보였다.(프롬프트 유해도 수치 최대일 때 제외)
(→ 프롬프트 만으로 문장의 understanding을 높일 수 있지만, prompt로 semantic 공간에 마진을 넓히는 CL을 하지 않으면 결국 해결되지 않음 → CL + prompt를 같이 하는 연구 good! )
- 프롬프트의 유해도가 높아질수록 기계가 생성하는 문장의 유해도도 또한 높아졌다.
한계
- 영어에 대한 측정만 시도함. 전세계 언어에 적용하는 것은 성급한 일반화일 수 있음.
- 공정한 벤치마크에 대한 표준화가 부족함.
- 무엇이 NLP의 편향성을 악화시키는지에 대한 이해가 부족함.
- 편향된 언어에 대한 포괄적인 이해 부족.
→ 이러한 벤치마크 셋이 많이 나와야함, 앞으로도 중요한 이슈!
9. Ethical Considerations
- AI의 성능이 높아짐에 따라 헬스케어나 교육 분야에도 활용되고 있음.
- 그러나 앞서 살펴본 선입견이 관련 태스크에 악영향을 미칠 수 있음.
- PaLM이 유해한 데이터에 노출되는 것은 어쩔 수 없음. 필터링을 해도 문제는 사라지지 않음.
- 현재 많이 활용되는 벤치마크도 이를 측정하기 힘듦.
- PaLM의 훈련 데이터셋은 좋은 데이터로 어느 정도 필터링된 데이터임. 따라서 비속어 등 소수의 언어습관에 대해 한계를 가질 수밖에 없음. 비영어권 언어에 대해서도 같음.
- 틀린 정보를 생산하는 등의 바람직하지 않은 방향으로 사용될 수 있음.
- 소프트웨어 개발에 활용 시에도 시큐어 코딩이 되었는지, 확실히 목표한 동작을 하는지 등의 걱정거리가 존재한다.
10. Related Work
- 트랜스포머 아키텍쳐가 언어 모델에 거대한 영향을 미쳤다...
- BERT와 GPT가 성능의 최고를 찍었다...
- 모델 텐서를 여러 가속 칩에 나누는 기술이 발전했다...
- 등등.. 개론적인 이야기.
11. Open Questions in Scaling
남은 이야기들.
모델 성능 향상에 기여한 네 가지 핵심 축.
- 모델의 크기
- 훈련 데이터셋의 규모
- 훈련 데이터셋의 질
- 계산 없이 모델의 수용량 늘리기(즉, sparse model)
모델의 크기와 훈련 데이터셋 규모의 상관 관계
- 예를 들어, [62B 규모의 7T 토큰 모델]과 [540B 규모의 780B 토큰 모델] 중 어떤 모델이 성능이 더 좋을 것인가?
- 이는 실험 비용이 너무 커서 현재로서는 알아내기 힘들다.
- 지금까지 알아낸 바로는, 비슷한 비용일 경우 모델 크기가 훈련 데이터 규모보다 중요하다.
- 하지만 이를 통해 상관관계를 밝힐 수는 없다.
- 현실적인 속도, 효율 문제와 데이터셋이 무한하지 않다는 문제가 있다.
모델 아키텍쳐, 사전학습 태스크, 옵티마이저 설정 등의 연구 과제가 있다.
12. Conclusion
PaLM
- 540B개의 파라미터, 780B개의 토큰, 트랜스포머 기반의 모델.
- 가장 많이 쓰이는 영어 NLP 태스크 29개 중 28개에서 최고 점수 경신.
- PaLM 5-shot 모델의 경우 어려운 NLP 태스크에서 사람보다 높은 평균 점수 기록.
- 코드 생성, 다국어 NLP, 기계번역 태스크에서 추가로 최고 점수 기록.
Reasoning task에서 인상적인 성과.
- chain-of-thought 프롬프트를 이용해서 논리적 추론 결과 놀라운 성능을 보임.
- 언어 모델이 언어를 사람처럼 정확하게 이해할 수 있음.
Few-shot 언어 이해 성능이 아직 최고점에 도달하지 못함.
- 8B, 62B, 540B 모델을 비교 결과 로그 선형 관계를 보임.
다른 태스크에도 언어 모델 이용 가능.
- 카테고리 분류, 회귀 등 언어 생성을 크게 필요로 하지 않는 태스크에서도 좋은 성능을 보임.
아직도 해야 할 것들이 많음.
- PaLM은 Pathway를 이용한 미래 거대 언어 모델의 첫 걸음일 뿐.
- 이상적인 신경망 아키텍쳐, 훈련 과정 등 연구할 것들이 많음.
끝.