Language Model 이전 글에서 Generative Model과 Discriminative Model 각각의 방법론에 대해 알아봤다. GPT의 G는 Generative Model을 뜻한다. GPT는 Language Model을 사용한다. Language Model의 training 방법은 둘 중에 전자를 택했다. 언어 모델은 단어 시퀀스에 확률을 할당하는 일을 하는 모델을 뜻한다. 가장 보편적으로 사용되는 언어 모델은 이전 단어들이 주어졌을 때 다음 단어를 예측하도록 하는 것이다. GPT1의 핵심은 Language model의 학습 방법으로, 엄청난 데이터를 통해 뛰어난 모델을 만드는 것이 핵심이다. 또한 GPT는 순방향 언어 모델이다. 이는 이전 단어들(컨텍스트)이 주어졌을 때 다음 단어를 맞히..
Generative model vs Discriminative model 분류 모델의 방법론은 크게 Generative model과 Discriminative model로 나뉜다. 각각의 방법론에 대해 알아보자. Discriminative model 어떤 입력값(input) \(x\)가 주어졌을 때, 그 결과값(label)이 \(y\)일 확률, 즉 조건부확률 $$P(y|x)$$를 알아내는 방법이다. 이 방식의 머신러닝은 아래의 방법으로 이루어진다. 특정 입력값 $x$에 대한 조건부확률분포를 만들어낸다. 조건부확률분포에 근거해서 $x$와 $y$에 대한 벡터를 만들어낸다. $x$값들에 대한 성질을 가장 잘 구분할 수 있는 구분선(decision boundary)를 만든다. 만들어진 선을 기반으로 얼마나 멀리..
엘모는 세서미 스트리트의 캐릭터다. TV는 아닌 것 같은데 어디서 봤을까...? 그렇다! Sake L의 노동요에서 본, 핵폭발을 배경으로 하고 있는 그 캐릭터다. 이후 등장하는 임베딩 모델인 버트도 세서미 스트리트에 등장하는 캐릭터 이름을 땄다. 문맥을 반영한 워드 임베딩의 필요성 실제 문장에서는 같은 단어라도 문맥에 따라 임베딩을 다르게 해야 할 때가 많다. 이는 다의어에 대해 임베딩할 때 많이 발생한다. ‘고소하다’라는 단어는 법대로 하자는 뜻과 고소한 맛이라는 뜻을 가지고 있는데, Word2Vec과 GloVe에서는 이를 문맥에 따라 제대로 반영하지 못하고 다른 의미인데도 같게 임베딩해버린다. 같은 표기여도 다르게 임베딩할 수 있도록 문맥을 고려해서 임베딩하자는 아이디어가, 문맥을 반영한 워드 임베딩..
자연어처리 바이블, 딥 러닝을 활용한 자연어 처리 wikidocs 등을 참조해서 공부하며 정리했습니다. 과거의 단어 임베딩 기술이 채택했던 아이디어와 각 알고리즘의 단점을 개선하고자 했던 방법들을 알아본다. 0. 요약 Word2Vec 이전 1990년대 초부터 널리 사용 잠재 의미 분석(latent semantic analysis, LSA), 잠재 디리클레 할당(latent dirichlet allocation, LDA) 활용 Word2Vec 단어 임베딩 열풍을 불러옴 ELMo 이전까지의 임베딩은 단어 단위 임베딩 2013년도 Mikolov et al.이 발표한 두 편의 논문에서 제안된 알고리즘의 이름 두 개 계층을 사용하는 얇은 것 : 학습 방법이 단순해서 더 많은 데이터를 활용할 수 있고 성능 향상됨...
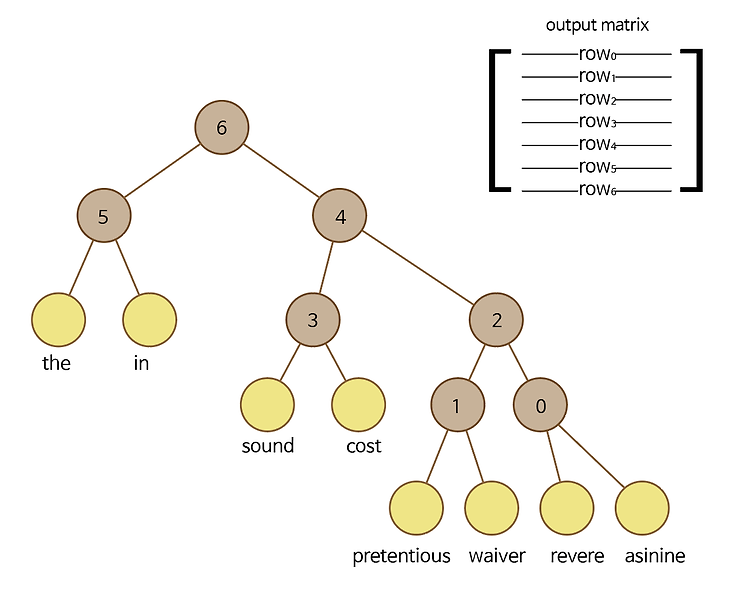
계층적 소프트맥스(Hierarchical Softmax, HS)란? 기존 softmax의 계산량을 현격히 줄인, softmax에 근사시키는 방법론이다. Word2Vec에서 skip-gram방법으로 모델을 훈련시킬 때 네거티브 샘플링(negative sampling) 방법과 함께 쓰인다. 어떤 건지 알아보자. 내용은 유튜브 ChrisMcCormicAI 채널의 설명을 참조했다. 기존 소프트맥스를 Word2Vec에 적용할 때의 문제점 우리가 아는 일반적인 softmax 함수를 MNIST와 같은 간단한 데이터셋에 적용할 때는 문제가 없었다. MNIST는 주어진 그림을 0부터 9까지 분류하는 문제였으므로 output이 10개면 충분했다. 하지만 Word2Vec 훈련 시에는 output의 개수가 Vocabulary..
다루는 내용 문맥 자유 언어 문맥 자유 문법 촘스키 정규형 CYK 알고리즘 문맥 자유 언어(Context-Free Language, CFL) 문맥 자유 언어(Context-free language, CFL)는 문맥 자유 문법이 생성하는 형식 언어이다. (같은 문법이 다른 언어를 생성할 수도 있다.) 문맥 자유 문법(Context-Free Grammar) 문법 \( G=(N, \Sigma, R, S) \) 에서 모든 생성 규칙이 $$ A\,\to\, w $$ 의 형태이면 \(G\)를 문맥 자유 문법(Context-free grammer, CFG) 라고 한다. 이때 \( A \in N \) 이고, \( w \in (N\cup \Sigma)^{*} \) 이다. 여기서 \(N\)은 a finite set of ..
오토마타 이론(Automata Theory)이란? 계산 능력이 있는 추상 기계와 그 기계를 이용해서 풀 수 있는 문제들을 연구하는 컴퓨터 과학의 한 분야이다. 추상 기계를 오토마타(Automata, 복수형) 또는 오토마톤(Automatnon, 단수형) 이라고 한다. 기계는 일반적으로 유한한 상태의 집합을 갖고 있다. 유한한 개수의 상태를 가질 수 있는 기계를 유한 상태 기계(finite-state machine), 오토마톤을 유한 오토마톤(finite automaton)이라 한다. 기계는 입력에 따라 현재 상태에서 다음 상태로 전이하며 출력을 내놓는다. 이는 계산 문제를 해결할 능력과 같다. 특정한 유한 오토마톤은 어떤 사건(event)에 의해 현재 상태(current state)에서 다른 상태로 변화할..
이번 장에서는 구문 분석의 대략적인 분류와 이론을 다룬다. A. 구구조 구문 분석 - 규칙 기반 - 통계 기반 - 딥러닝 기반 B. 의존 구조 구문 분석 - 구구조 구문 분석과의 차이 - 의존의 종류 - 분석 방법 C. 중의성 구구조 구문 분석 구구조란 문장의 요소들이 서로 짝을 지어 구와 절을 이룸으로써 형성되는 구조이다. 분석 방법으로는 규칙 기반, 통계 기반, 딥러닝 기반 분석이 있다. 규칙 기반 구구조 구문 분석 S → NP VP VP → V NP NP → DT NP S는 Sentence, NP는 Noun Phrase, VP는 Verb Phrase, DT는 Determiner를 의미한다. 이 문법 규칙을 'John hit the ball.'이라는 문장에 적용하면 위의 그림과 같은 분석 트리를 얻을..