
비연합(nonassociatiive) 구조: 하나의 상황에 대해서만 행동을 학습하는 단순화된 구조.
다중 선택 문제(k-armed bandit problem)
k개의 서로 다른 옵션이나 행동을 중에 한 가지를 선택하는 문제.
매 선택 후에는 보상이 주어진다. 이 보상은 행동에 따라 결정되는 정상확률분포(stationary probability distribution)로부터 얻어진다.
예를 들어, 1000번 선택할 때 주어지는 보상 총량의 기댓값을 최대화하는 것이 목표이다.
가치(value): 다중 선택 문제에서 k개의 행동 각각에 할당된, 그 행동이 선택되었을 때 기대할 수 있는 평균 보상값.
$$ q_*(a)= \mathbb{E}[R_t|A_t=a] $$
\( A_t \)는 시간단계 \( t \)에서 선택되는 행동이다.
\( R_t \)는 그에 따른 보상이다.
\( q_*(a)\)는 행동 \( a\)가 선택되었을 때 얻는 보상의 기댓값이다.
\( Q_t(a)\)는 시간단계 \( t\)에서 추정한 행동 \( a\)의 가치이다. 추정값 \( Q_t(a)\)가 기댓값 \( q_*(a)\)와 가까워질수록 정확한 추정이 된다.
행동 가치 방법(action-value method)
행동의 가치를 추정하고 추정값으로부터 행동을 결정하는 방법을 행동 가치 방법이라고 한다.
가치의 추정값은 받은 보상의 산술평균을 계산하는 것이다.
$$ Q_t(a) =\small{\frac{\text{시각 t 이전에 취해지는 행동 a에 대한 보상의 합}}{\text{시각 t 이전에 행동 a를 취하는 횟수}}} $$ $$ =\frac{\sum_{i=1}^{t-1}{R_i\cdot \mathbb{1}_{A_t=a}}}{\sum_{i=1}^{t-1}{\mathbb{1}_{A_t=a}}} $$
여기서 \( \mathbb{1} \)은 조건이 참이면 1을, 거짓이면 0을 갖는 변수이다.
탐욕적 방법: 가장 간단히 행동을 선택하는 방법. 행동의 추정 가치가 최대인 행동을 선택한다.
$$ A_t=\underset{a}{\operatorname{argmax}}Q_t(a) $$
하지만 즉각적인 보상의 최대화가 아니라, 실제로는 더 좋은 결과를 낼 수 있을지도 모르는 더 열등한 행동을 선택할 수도 있다. 즉, 탐험적 선택을 할 수도 있다. 이때 대부분은 탐욕적 선택을 수행하고 가끔 탐험적 행동을 선택하는 방법이 다음에 소개할 엡실론 탐욕적 방법이다.
엡실론 탐욕적(\(\epsilon\)-greedy) 방법
상대적 빈도수 \(\epsilon\)을 작은 값으로 유지하면서 탐욕적 선택 대신 모든 행동을 대상으로 무작위 선택한다.
이 방법은, 이후 단계의 개수가 무한으로 커지면 모든 행동이 선택되는 횟수가 무한이 되어 모든 \(Q_t(a)\)가 \(q_*(a)\)로 수렴한다는 것이다.
하지만 이는 단지 수렴성을 보장할 뿐, 효용성을 말하는 것은 아니다.
10중 선택 테스트
- 탐욕적 행동 가치 방법과 엡실론 탐욕적 행동 가치 방법을 비교하기 위한 방법이다.
- a=1, 2, ..., 10 에 대해 각각의 행동 가치 \(q_*(a)\)는 평균이 0이고 분산이 1인 정규분포에 따라 선택된다.
- 실제 보상값 \(R_t\)는 평균이 \(q_*(A_t)\)이고 분산이 1인 정규분포로부터 선택된다.
- 1000번의 시간 단계를 통해 스스로 발전한다. 이를 한 번의 시행으로 치고, 서로 다른 10중 선택 문제를 2000번 독립적으로 시행하여 평균 결과를 측정한다.

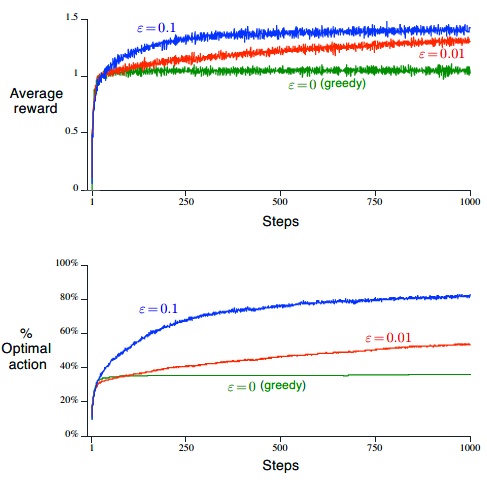
결과
- \(\epsilon=0.1\)일 때가 가장 성능이 좋은 것으로 보인다.
- 하지만 무한히 탐험한다 해도 최적 행동을 선택한 시간 단계의 비율은 91%에 미치지 못할 것이다. 왜냐면 열 번 중에 한 번은 임의로 행동을 정하기 때문이다.
- 따라서 \(\epsilon=0.01\)을 적용하면 최적 행동을 찾는 것은 느리지만 결국에는 더 좋은 결과를 낼 것이다.
논의사항
- 보상의 분산이 크다면, 예를 들어 10이라면 보상에 잡음(noise)가 더 많이 낄 것이므로 엡실론 탐욕적 방법이 탐욕적 방법보다 훨씬 더 좋을 것이다.
- 보상의 분산이 0이라면, 탐욕적 방법은 곧바로 최적 행동을 찾아낼 것이기 때문에 탐욕적 방법이 좋다.
- 이처럼 결정론적(deterministic)인 상황에서도 문제가 비정상적(nonstationary), 즉 시간에 따라 행동 가치의 참값이 변한다면 탐험이 필요하다. 왜냐하면 어떤 비탐욕적 행동이 더 큰 가치를 갖도록 변했는지 확인해야 하기 때문이다.
'NLP lab > 강화학습' 카테고리의 다른 글
| 01. 틱택토로 알아보는 강화학습 [CH1 소개] (0) | 2022.04.18 |
|---|---|
| 00. 강화학습 용어 한국어 번역 정리 (0) | 2022.04.18 |